opencode使用系列课程连载(6):我怎么用 opencode-一个老程序员的真实工作流
Excerpt
我怎么用 OpenCode:一个老程序员的真实工作流写代码、写文档、画图、提速、省 token 的一线经验前面五篇,基础、进阶、性能优化与故障排查、skills、MCP,其实已经把 OpenCode 的主要能力讲得差不多了。到这一步,很多朋友面临的问题已经不是“不会用”,而是“会用,但还没用顺”。这两种状态,差的往往就是一整套工作习惯。我自己是写代码出身,后面也做架构、方案、技术文档、图纸和一些写
我怎么用 OpenCode:一个老程序员的真实工作流
写代码、写文档、画图、提速、省 token 的一线经验
前面五篇,基础、进阶、性能优化与故障排查、skills、MCP,其实已经把 OpenCode 的主要能力讲得差不多了。到这一步,很多朋友面临的问题已经不是“不会用”,而是“会用,但还没用顺”。这两种状态,差的往往就是一整套工作习惯。
我自己是写代码出身,后面也做架构、方�案、技术文档、图纸和一些写作工作。看一个工具值不值得留下来,我主要就看三件事:顺不顺手,够不够用,划不划算。
所以这一篇,我不打算再讲一遍 OpenCode 有哪些能力,而是想老老实实聊聊:我现在主要拿它做什么,我为什么会这么用,我有哪些比较顺手的习惯,以及哪些地方我觉得值得你少走点弯路。
我主要拿 OpenCode 做什么
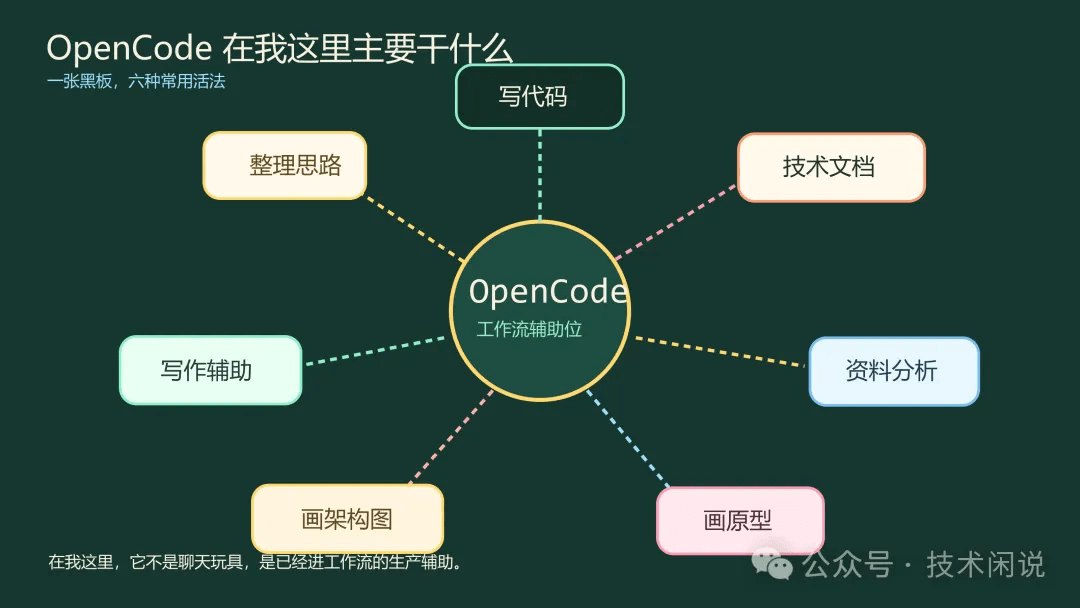
如果只说一句话,那就是:我已经把它放进日常工作流里了。
比较高频的场景,大概有这几类:
-
写代码,或者更准确一点说,辅助我完成从理解问题到落代码、再到验证结果的一整段工作。
-
写技术文档,比如方案说明、接口说明、调研文档、复盘材料。
-
做资料分析,尤其是需要看多份材料、做归纳、抽取重点的时候。
-
画原型,快速把一个界面或者交互想法摆出来。
-
画架构图,把脑子里那团抽象关系尽快落成图。
-
做写作辅助,包括列提纲、改段落、调整语气、压缩废话。
以前很多人看这类工具,容易把它当成一个“功能集合”。我自己的体感不是这样。对我来说,它更像一个坐在旁边的辅助位:整理思路、搬文档、去画图,顺手再提醒你,需求还没讲清楚,先别急着动手。
写代码这件事,我更看重顺手和够用
先说结论:在写代码这件事上,我现在更常用的是 superpowers。
原因并不复杂,它够轻,也够用,而且不怎么折腾人。我一直有个很朴素的习惯:工具不要抢活,要帮活。
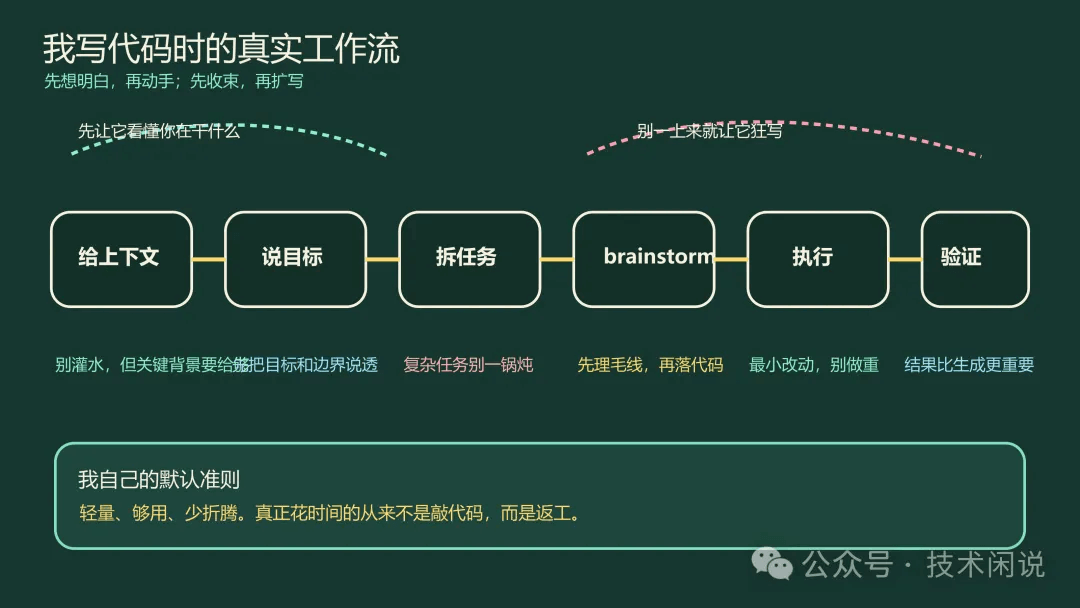
我一般怎么让它参与编码
我不太喜欢一上来就扔一句“帮我写个 xx 功能”。这种问法最大的问题,不是它写不出来,而是它会把你没想清楚的部分一起脑补进去。脑补得不对,返工成本往往比先说清楚更高。
我现在更常见的用法是这样的:
-
先把上下文给够,但不灌水。项目背景、当前目标、限制条件、已有文件位置,这些该给就给。
-
先让它理解问题,再让它动手。也就是先对齐目标、边界、风险点。
-
复杂一点的任务,我会先拆一下。不是为了显得专业,而是因为不拆,它很容易一口气做重。
-
落代码之前,尽量先把思路聊顺。这个阶段我最喜欢的就是
brainstorm。
brainstorm 这个 skill 我是真的挺喜欢。很多时候我们不是不会写代码,而是脑子里那团毛线还没理顺。你让模型直接开写,它常常会写出一种“看起来很忙、实际不太对”的东西。先聊清楚需求、约束、方案和取舍,后面执行反而更稳。有时候真正卡住的也不是语法和框架,而是“这件事到底该怎么切”。先把问题切开,比直接往文件里倒代码值钱得多。
为什么我会偏向 superpowers
我个人比较偏爱轻量、直接、能干活的东西。superpowers 给我的感觉就是:轻,快,够用,尤其适合日常开发这种高频但不一定高仪式感的场景。你让它帮你理思路、拆任务、查文件、做小范围修改、补文档、顺手验证,它通常都能接得住。
很多朋友也会拿它和 gstack 比。我这里不想写成拉踩文,因为两者不是一个思路。
| 维度 | superpowers | gstack |
|---|---|---|
| 整体体感 | 轻量、直接 | 更完整,也更重 |
| 上手门槛 | 相对低 | 相对高 |
| token 消耗 | 就我的体感来说更克制 | 通常更容易吃上下文 |
| 日常编码顺手度 | 高 | 视流程而定 |
| 更适合的场景 | 常规开发、思路整理、轻量协作 | 更重流程、更完整联动 |
| 我自己的使用频率 | 高 | 按需 |
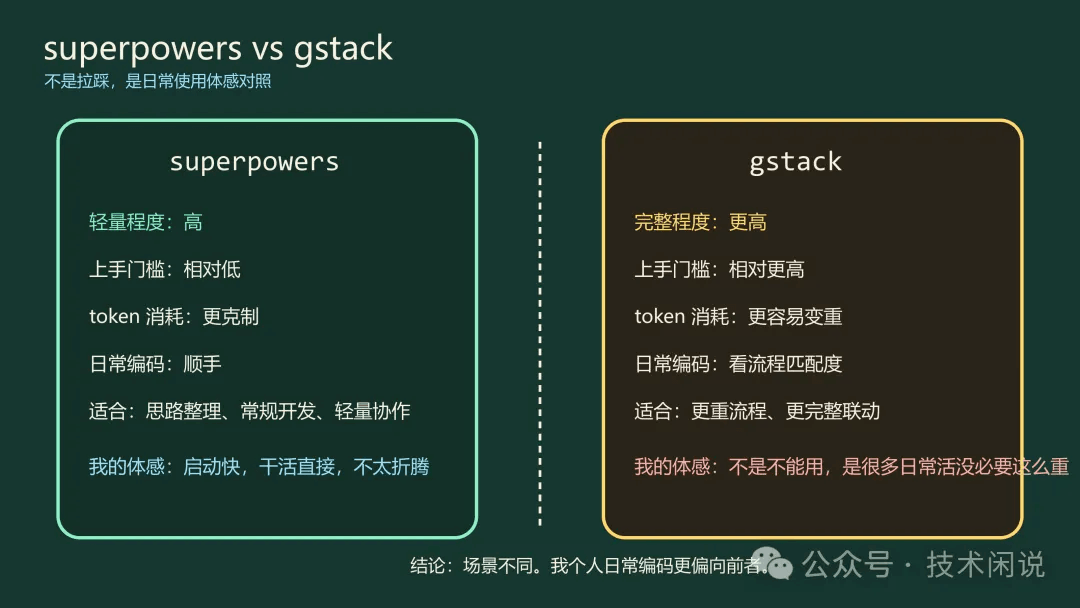
我的态度很简单:不是说 gstack 不好,而是对我这种日常开发使用习惯来说,很多时候 superpowers 已经够用了,而且更顺手。越重的东西,一般越吃 token,也越容易把一个本来可以快速解决的小动作,拖成一套完整流程。
写代码时我自己的几个习惯
这里不讲大而全,就说几个我自己真的经常用的。
第一,别让它替你猜核心约束。比如你到底要最小改动,还是允许重构;是修 bug,还是顺手优化;只动一个文件,还是可以连着测试一起改。这些你不说,它就会猜。猜不准就是返工。
第二,别一上来就让它写很大一坨。先让它看懂,再让它动刀。你会发现它一旦先把上下文咬住,后面的修改质量会稳很多。
第三,复杂任务一定要拆。拆不是为了形式,而是为了减少跑偏。一个任务里同时塞进“理解需求、改代码、补测试、写文档、顺手再优化一下结构”,最后经常哪个都不踏实。
第四,验证比产出更值钱。能不能跑、有没有漏边界、会不会打到别的地方,这些都比“它一分钟写了多少行代码”重要。说到底,工程不是比生成速度,是比交付可靠性。
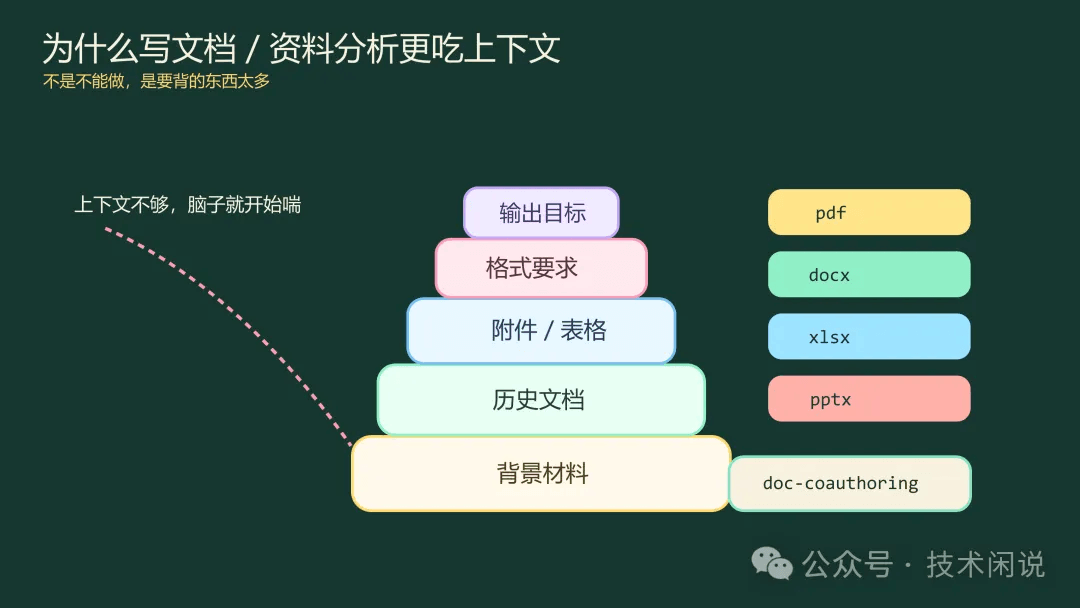
写文档和做资料分析,真正卡人的往往不是能力,而是上下文
如果说写代码这件事,我最看重的是顺手和够用;那到了写文档、做资料分析这类活,我最先看的就是:上下文扛不扛得住。因为这类任务往往不是一份输入、一份输出那么简单,背景材料、历史讨论、旧文档、附件、格式要求、受众差异、语气要求、输出模板,一层层叠起来,很容易把上下文吃满。
所以我自己的建议一直比较直接:如果你打算认真拿 OpenCode 写技术文档,或者做一些资料分析,尽量优先选支持大上下文的模型。以我自己的体验,GPT-5.5 和 GLM-5 这一类大上下文模型,用来处理连续读材料、反复改文稿这类活,会更顺手一些。这里我说的不是谁绝对最强,而是在我常做的技术文档和资料分析场景里,它们更容易把长上下文接稳,不容易聊着聊着就丢重点。
很多人会把这类任务做得很难受,不是因为工具没能力,而是因为环境没铺平。它不是不能干,而是干得慢、干得别扭,还特别费上下文。
这类任务一定要装的 skill
如果你准备长期写文档,或者经常跟资料、附件打交道,那几类文档处理相关的 skill,真的建议提前装好:
-
pdf -
docx -
xlsx -
pptx
这几个东西,看名字很朴素,但解决的问题很实际:不用每次先把文档转换来转换去,也不用自己手抄一遍内容给它看。尤其面对成套资料、会议材料、汇报稿、分析表格的时候,这类能力基本不是可选项,而是效率底座。说白了,它们不是给文章加花活的,而是帮你把文档类脏活累活先接过去。
这里我尤其推荐 doc-coauthoring。这个 skill 我觉得非常值钱,它不是简单帮你“写一段文字”,而是更像一个文档协作者:帮你理结构、问关键问题、补齐读者视角,把一份文档从“能看”往“好用”推一把。写文档最麻烦的往往不是敲字,而是你以为自己写清楚了,读的人其实并没有接住。
Python 环境最好提前铺好
还有一个很现实的建议:提前把 Python 和相关文档库装好。
比如这些:
-
python-docx -
python-pptx -
python3-pymupdf -
python3-openpyxl -
python3-xlrd
原因很简单,文档处理这类活,很多 skill 最终还是要借助这些库把事情做扎实。环境没准备好,它也不是完全不能干,但会明显变笨。我自己甚至会直接告诉它:这些库我已经装好了,你直接用。
节省 token 和提速,靠的不是玄学,是工作习惯
这个话题很多人喜欢讲得很神秘,仿佛有一套独门口诀。其实真没有,核心就一句话:别让一个会话背太多不该它背的东西。
第一,会话长了就汇总,然后重开。 这招非常土,但很有效。你不要迷信一条线程从头干到尾。很多时候上下文越拖越长,速度会慢,回答也会开始发散,甚至连重点都抓不住。与其硬扛,不如把已经形成的结论收束一下,开个新会话继续干。
第二,让工具帮你记,不要让模型硬背。 该落盘的落盘,该汇总的汇总,该进文档的进文档。你把关键结果沉淀下来,下一轮只带必要信息继续,这比每次都把一整段历史塞进去强多了。
第三,DCP 这种东西值得装。 它本质上就是一个上下文管理插件,能把长会话里的关键结论压缩沉淀下来,让你重开会话时不用再背整段历史。尤其是一个主题要来回迭代好几轮的时候,速度和稳定性都会好很多。
第四,能分段做的事,别一锅炖。 这不只是为了省 token,也是为了让结果更稳。你把任务拆开,它每一步的目标就更清楚,出错面也更小。
很多工程问题,最后拼的都不是“最强能力”,而是“长期稳定的工作节奏”。AI 工具也是一样。你要是每次都让它扛满上下文、一次解决所有问题,它很�快就会提醒你:这活安排得不科学。
画原型和架构图,别硬拧,交给合适的 MCP
这部分我反而想说得简单一点。
画原型,我建议直接用 pencil MCP。画架构图,我建议直接用 drawio MCP。这两类任务本来就是图形问题,你非要全靠纯文本去硬拧,最后通常是又慢又别扭,还容易把本来很直观的东西讲复杂。
我自己的习惯就是:该文本的事交给文本工具,该图形的事交给图形工具。不要为了统一入口,把所有任务都塞进同一种表达方式里。
这两个 MCP 的配置其实都不算难,前面教程里也已经讲过了。这一篇就不展开重复,重点还是提醒一句:能画出来的东西,就别长期停留在嘴上。
我文中提到的这些 skill 和工具,去哪里装、去哪里学
这部分我建议你直接收藏。很多朋友不是不想装,而是看完文章之后,不知道下一步该去哪里找入口。
1. superpowers
这是我文里最推荐的一套轻量技能包。
-
官方 OpenCode 说明:https://github.com/obra/superpowers/blob/main/docs/README.opencode.md
-
OpenCode 官方 Skills 文档:https://opencode.ai/docs/skills/
如果你是 OpenCode 用户,最值得先看的就是它那份 README.opencode.md,安装和使用入口都比较直接。
2. DCP
我文里提到的 DCP,本质上是一个给 OpenCode 做上下文管理和压缩的插件。
我怎么用 OpenCode:一个老程序员的真实工作流
-
项目主页:https://github.com/Opencode-DCP/opencode-dynamic-context-pruning
-
README:https://github.com/Opencode-DCP/opencode-dynamic-context-pruning/blob/master/README.md
-
OpenCode 官方插件文档:https://opencode.ai/docs/plugins/
如果你经常开长会话,或者很在��意 token 消耗和会话稳定性,这个插件很值得研究一下。
3. pdf / docx / xlsx / pptx / doc-coauthoring 这类 skill
这里我得说清楚一点:这几个更像是文档处理和文档工作流相关的 skill 类别,不是 OpenCode 官方内置的一组固定标准包。
所以更靠谱的顺序是:
-
先看 OpenCode 官方 Skills 文档,弄明白 skill 的目录结构和加载机制:https://opencode.ai/docs/skills/
-
再去你自己的 skill 包、团队 skill 仓库,或者社区公开 skill 仓库里按关键词找:
pdf、docx、xlsx、pptx、doc-coauthoring -
不同来源的 skill 可能名字一样、实现不一样,装之前最好先看一下说明
换句话说,这一类不是“只有一个官方出处”,而是“先学会技能机制,再去装你需要的那类技能”。
4. pencil MCP
这个是我文里推荐用来画原型的。
5. drawio MCP
这个是我推荐用来画架构图的。
-
OpenCode MCP 配置文档:https://opencode.ai/docs/mcp-servers/
6. 一个总入口:OpenCode 官方文档
如果你刚准备系统折腾这些能力,我建议至少先把这 3 篇官方文档过一遍:
-
MCP Servers:https://opencode.ai/docs/mcp-servers/
你把这三块先弄明白,再回来看各种社区 skill、插件和 MCP,会顺很多。
最后说几句
写到这里你应该也能看出来,这一篇我想讲的并不是某个命令、某个插件、某个技巧本身有多神,而是一个更朴素的事情:工具最后是要长进你的工作习惯里的。
我现在用 OpenCode,已经不太会把它当成一个新鲜玩具去看了。它更像一套趁手的工作辅助:写代码的时候帮我收束问题,写文档的时候帮我抬一把上下文,画图的时候把抽象想法快点落地,写作的时候帮我去水分、理结构。
当然,这也不是标准答案。每个人手上的项目、团队节奏、工具偏好都不一样。你未必要照着我这套来,甚至有些地方你可能会跟我选得不一样,这都很正常。
但如果前五篇让你知道了 OpenCode 能做什么,那我希望这一篇至少能再往前推一步:怎么把它用成自己真正顺手的一套工作流。
如果能帮你少走一点弯路,那这篇就算没白写。